The free ride is over: from the looping agent to the orchestrator
ContenidoContents
Today a former boss, and friend, posted something on LinkedIn. On June 1 GitHub Copilot’s new pricing kicked in, and in a single day he had burned through a third of his Pro+ subscription, the $39-a-month one. The month before, he hadn’t used it up in 31 days. “I knew a hike was coming, but I didn’t expect it to be this much.” The slap in the face.
It’s not an isolated case. Under the new pricing model, anyone relying on agentic workflows has found bills ten to fifty times higher. Weekly limits by token consumption have arrived, the fallback model is gone, and the Opus models have left the Pro plan (they only remain in Pro+). The AI free ride is over.
What interests me isn’t the price hike, but what my former boss said right after: that this past year, coding with agents, has been his most productive stage… and he was working alone. His role has shifted to architect and, at the same time, the QA that signs off on each phase. I agree with every word. And that’s why the hike doesn’t feel like just a wallet problem to me: it’s a filter.
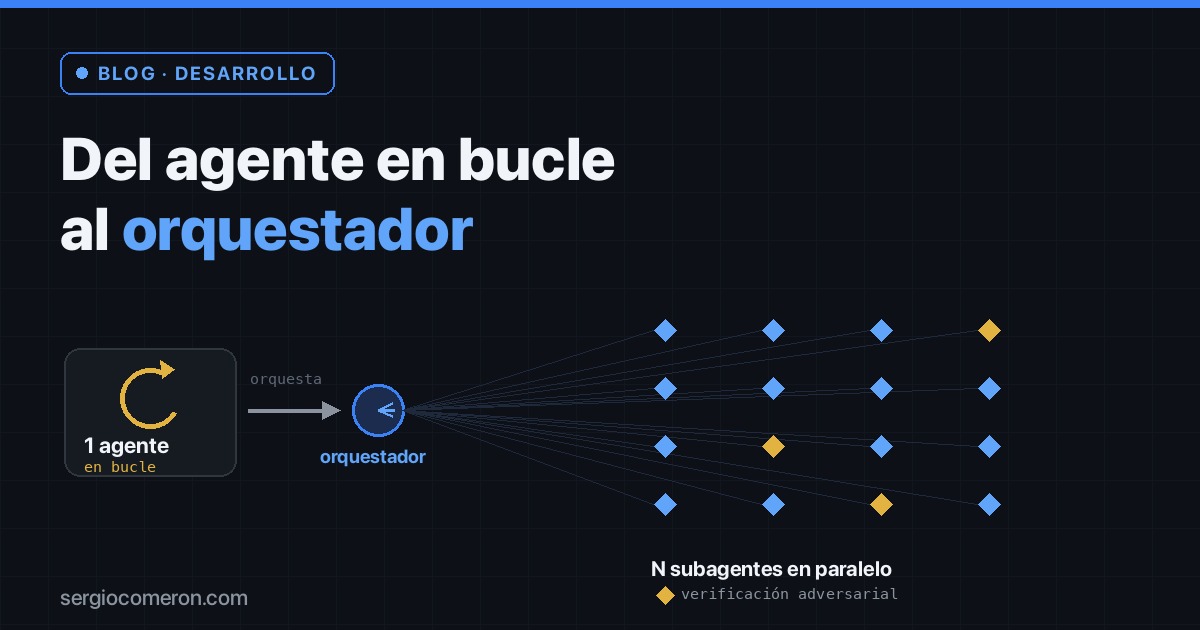
The looping agent doesn’t scale (technically or economically)
A lot of people use the agent as a glorified autocomplete: “do this for me,” and let’s see what comes out. Working that way, in a loop and with no direction, the agent has two flaws.
The technical one is familiar to anyone who has pushed it hard: when the error is ambiguous or domain knowledge is needed, it gets stuck —it makes a change, sees the tests fail, reverts, tries a variation, fails again— and falls into a cycle. It reads the repo but doesn’t grasp the architectural intent, so it duplicates a helper that already existed or ignores your naming conventions. And with the context window saturated, the moment the task touches ten or fifteen files, it loses track of what it had already decided.
The economic one is new, and it’s the one that hurts this month. Every turn of that loop —reading files, generating a plan, editing, reading the error, retrying— consumes tokens. While inference was cheap, overspending didn’t matter. Now every unnecessary iteration is paid for, and an agent that takes fifteen turns where it should take three shows up directly on the bill. Cost has turned a quality problem into a money problem.
Orchestrating for real: getting into the detail
The first answer is to put on the orchestrator hat, and it’s worth pinning down what that means, because it’s not “writing better prompts.” It’s designing the flow:
- Decompose the task into phases, each with a clear goal, instead of dropping one giant request.
- Route the context: give each phase only what it needs. Not too little (it hallucinates) nor too much (it gets distracted and you pay for the context on every call).
- Pick the model per phase: a fast, cheap model for the mechanical stuff (renames, boilerplate, formatting) and reserve the expensive one for hard reasoning. Firing Opus at everything is like paying an architect to paint the wall.
- Add verification gates: a phase shouldn’t advance until another checks its output (tests, linter, or a second agent that reviews it).
It is, literally, directing juniors: if you don’t write the brief well, the result is unpredictable —and expensive—. The difference between a session that converges in three steps and one that takes fifteen turns running up the meter is almost never the model; it’s how you split the work. Whoever orchestrates well absorbs the price hike. Whoever doesn’t, pays it in full.
Dynamic Workflows: when the model orchestrates itself
And here’s the twist that has me hooked. That work of getting into the detail of every step is also starting to be delegated… to the model itself.
Anthropic released Claude Opus 4.8 on May 28 —just 41 days after 4.7— with a preview feature called Dynamic Workflows. Instead of one agent iterating serially, the model writes an orchestration script and runs it: it spins up tens to hundreds of subagents in parallel (the cap is a thousand per run, with about ~16 running at once), has them attack the problem from independent angles, deploys adversarial agents that try to refute each finding, and iterates until the answers converge before handing you anything.
What’s powerful is that it’s not a dumb “do N things in parallel.” The patterns underneath are the ones you’d apply by hand if you had the time and ten clones:
- Fan-out: N agents searching the same thing in different ways (by container, by content, by entity), each blind to what the others see.
- Pipeline instead of a barrier: each finding moves to the next stage as soon as it’s ready, without waiting for all the others. That way the total time is the slowest chain, not the sum.
- Majority adversarial verification: for each finding, several independent skeptics try to knock it down; if the majority refutes it, it’s discarded. That’s what kills the “plausible but wrong” ones.
- Loop-until-dry: keep searching until several consecutive rounds turn up nothing new, so you don’t fall short on the long tail of edge cases.
- Budget: scale the number of agents to the spend you set. You decide how much the answer is worth.
Conceptually, the script the model writes for an exhaustive review comes out something like this:
1const dimensions = ['security', 'concurrency', 'performance']
2
3// For each dimension: find → verify each finding in parallel.
4// The pipeline does NOT wait for all of them to finish before verifying.
5const findings = await pipeline(dimensions,
6 dim => agent(`Find ${dim} bugs in the diff`),
7 list => parallel(list.map(bug =>
8 agent(`Try to REFUTE this bug: ${bug}. Default to false if unsure.`)
9 ))
10)
11const confirmed = findings.flat().filter(f => f.isReal)
Where it shows the most is in what used to be a slog: repository-scale migrations (hundreds of thousands of lines from start to finish), reviews that touch all of the code at once, or sweeps where a single agent would have gotten lost. And it connects with another improvement in this version that’s no coincidence: Opus 4.8 is about four times less likely to wave through flawed code, with a more than tenfold drop in overconfidence. It makes sense: when your own system carries adversarial verification inside, far fewer things slip past.
Using it in Claude Code, the feeling is strange: I have to get into the detail less and less. Where I used to dictate —do this, then that, verify the other thing— now I describe the goal and it’s the model that splits the work among its swarm and self-corrects. The question stops being “what steps do I dictate?” and becomes “what do I want to achieve, and how do I verify it actually achieved it?”.
The new division of labor
The model orchestrating the steps doesn’t leave you without a job: it pushes you upward. You’re still the architect —deciding what to build and why— and the QA —checking that what’s built actually works—. No swarm of subagents delegates that. What changes is that the edge is no longer typing speed, or even prompt-craft: it’s systems thinking, knowing how to decompose a problem and how to verify an answer. Exactly the two things an agent —however many of them there are— still doesn’t decide for you.
The free ride is over. But whoever knows how to set up the orchestra won’t miss it.