Se acabó la barra libre: del agente en bucle al orquestador
ContenidoContents
Hoy un antiguo jefe, y amigo, ha publicado algo en LinkedIn. El 1 de junio entraron en vigor las nuevas tarifas de GitHub Copilot, y en un solo día se había fundido un tercio de su suscripción Pro+, la de 39 dólares al mes. El mes anterior no la había agotado en 31 días. “Sabía que venía una subida, pero no me esperaba que fuera tanto”. La bofetada.
No es un caso aislado. Con el nuevo modelo de precios, quien tira de flujos agénticos se ha encontrado facturas entre diez y cincuenta veces más altas. Han llegado los límites semanales por consumo de tokens, ha desaparecido el modelo de respaldo, y los Opus han salido del plan Pro (quedan solo en Pro+). La barra libre de la IA se acabó.
Lo que me interesa no es el tarifazo, sino lo que mi antiguo jefe contaba justo después: que este último año, programando con agentes, ha sido su etapa más productiva… y estaba él solo. Su papel ha pasado a ser el de arquitecto y, a la vez, el QA que aprueba cada fase. Suscribo cada palabra. Y por eso la subida no me parece solo un problema de cartera: es un filtro.
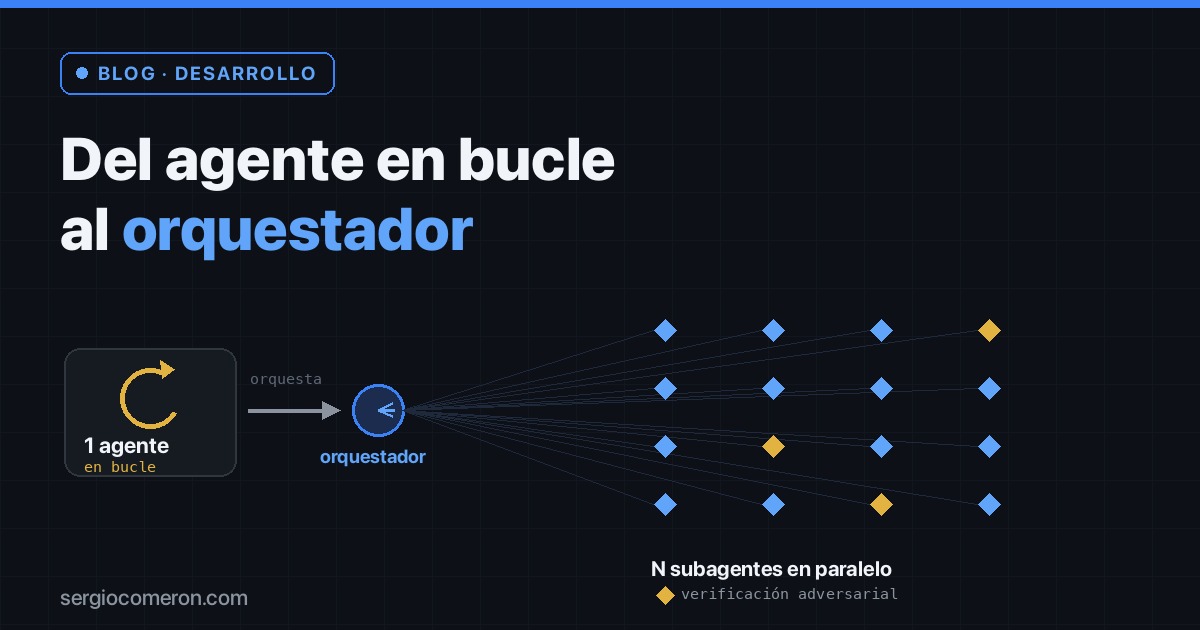
El agente en bucle no escala (ni técnica ni económicamente)
Mucha gente usa el agente como un autocompletado glorificado: “hazme esto”, y a ver qué sale. Trabajando así, en bucle y sin dirección, el agente tiene dos defectos.
El técnico lo conoce cualquiera que lo haya forzado: cuando el error es ambiguo o hace falta conocimiento del dominio, se atasca —cambia, ve fallar los tests, revierte, prueba una variante, vuelve a fallar— y entra en un ciclo. Lee el repositorio pero no entiende la intención arquitectónica, así que te duplica un helper que ya existía o se salta tus convenciones de nombrado. Y con la ventana de contexto saturada, en cuanto la tarea toca diez o quince ficheros, pierde el hilo de lo que ya había decidido.
El económico es el nuevo, y es el que duele este mes. Cada vuelta de ese bucle —leer ficheros, generar un plan, editar, leer el error, reintentar— consume tokens. Mientras la inferencia fue barata, daba igual gastar de más. Ahora cada iteración innecesaria se paga, y un agente que da quince vueltas donde debería dar tres se nota directamente en la factura. El coste ha convertido un problema de calidad en un problema de dinero.
Orquestar de verdad: bajar al detalle
La primera respuesta es ponerse el sombrero de orquestador, y conviene aterrizar qué significa eso, porque no es “escribir mejores prompts”. Es diseñar el flujo:
- Descomponer la tarea en fases con un objetivo claro cada una, en vez de soltar un encargo gigante.
- Rutear el contexto: darle a cada fase solo lo que necesita. Ni de menos (alucina) ni de más (se distrae y pagas el contexto en cada llamada).
- Elegir el modelo por fase: un modelo rápido y barato para lo mecánico (renombrados, boilerplate, formateo) y reservar el caro para el razonamiento difícil. Disparar Opus para todo es como pagar a un arquitecto por pintar la pared.
- Poner puertas de verificación: que una fase no avance hasta que otra compruebe su salida (tests, linter, o un segundo agente que la revise).
Es, literalmente, dirigir juniors: si no escribes bien el encargo, el resultado es impredecible —y caro—. La diferencia entre una sesión que converge en tres pasos y otra que da quince vueltas tirando del contador casi nunca está en el modelo; está en cómo repartiste el trabajo. El que orquesta bien absorbe la subida de precios. El que no, la paga entera.
Dynamic Workflows: cuando el modelo se orquesta a sí mismo
Y aquí está el giro que me tiene enganchado. Ese trabajo de bajar al detalle de cada paso también está empezando a delegarse… en el propio modelo.
Anthropic lanzó Claude Opus 4.8 el 28 de mayo —apenas 41 días después de la 4.7— con una función en preview llamada Dynamic Workflows. En lugar de un agente iterando en serie, el modelo escribe un script de orquestación y lo ejecuta: lanza de decenas a cientos de subagentes en paralelo (el tope está en mil por ejecución, con unos ~16 corriendo a la vez), los hace atacar el problema desde ángulos independientes, despliega agentes adversariales que intentan refutar cada hallazgo, e itera hasta que las respuestas convergen antes de devolverte nada.
Lo potente es que no es un “haz N cosas en paralelo” tonto. Los patrones que usa por debajo son los que aplicarías a mano si tuvieras tiempo y diez clones:
- Fan-out: N agentes buscando lo mismo de formas distintas (por contenedor, por contenido, por entidad), cada uno ciego a lo que ven los demás.
- Pipeline en vez de barrera: cada hallazgo avanza a la siguiente etapa en cuanto está listo, sin esperar a que terminen todos. Así el tiempo total es el de la cadena más lenta, no la suma.
- Verificación adversarial por mayoría: por cada hallazgo, varios escépticos independientes intentan tumbarlo; si la mayoría lo refuta, se descarta. Es lo que mata los “plausibles pero falsos”.
- Loop-until-dry: seguir buscando hasta que varias rondas seguidas no aporten nada nuevo, para no quedarse corto en la cola de casos raros.
- Presupuesto: escalar el número de agentes al gasto que le pongas. Tú decides cuánto vale la respuesta.
Conceptualmente, el script que escribe el modelo para una revisión exhaustiva viene a ser algo así:
1const dimensiones = ['seguridad', 'concurrencia', 'rendimiento']
2
3// Por cada dimensión: busca → verifica cada hallazgo en paralelo.
4// El pipeline NO espera a que terminen todas para empezar a verificar.
5const hallazgos = await pipeline(dimensiones,
6 dim => agent(`Busca bugs de ${dim} en el diff`),
7 lista => parallel(lista.map(bug =>
8 agent(`Intenta REFUTAR este bug: ${bug}. Por defecto, falso si dudas.`)
9 ))
10)
11const confirmados = hallazgos.flat().filter(h => h.esReal)
Donde más se nota es en lo que antes era una tortura: migraciones a escala de repositorio (cientos de miles de líneas de principio a fin), revisiones que tocan todo el código a la vez, o barridos en los que un solo agente se habría perdido. Y conecta con otra mejora de esta versión que no es casual: Opus 4.8 es unas cuatro veces menos propenso a dar por bueno código defectuoso, con una caída de más de diez veces en exceso de confianza. Tiene sentido: cuando tu propio sistema lleva la verificación adversarial dentro, dejas pasar muchas menos cosas.
Usándolo en Claude Code, la sensación es rara: cada vez tengo que bajar menos al detalle. Donde antes dictaba yo —haz esto, luego aquello, verifica lo otro—, ahora describo el objetivo y es el modelo quien reparte el trabajo entre su enjambre y se autocorrige. La pregunta deja de ser “¿qué pasos le dicto?” y pasa a ser “¿qué quiero conseguir y cómo verifico que de verdad lo ha conseguido?”.
El nuevo reparto
Que el modelo orqueste los pasos no te deja sin trabajo: te empuja hacia arriba. Sigues siendo el arquitecto —decidir qué construir y por qué— y el QA —comprobar que lo construido sirve—. Eso no lo delega ningún enjambre de subagentes. Lo que cambia es que el diferencial ya no es la velocidad tecleando, ni siquiera el prompt-craft: es el pensamiento de sistemas, saber descomponer un problema y saber verificar una respuesta. Justo las dos cosas que un agente, por muchos que sean, todavía no decide por ti.
La barra libre se acabó. Pero quien sepa montar la orquesta no va a echarla de menos.